


Part 17: Powering AI
The AI business is on fire


During the California Gold Rush, the population of San Francisco increased from about 1,000 in 1848 to 25,000 full-time residents by 1850. Miners lived in tents and wood shanties. When the rush began, the equipment needed for digging up and extracting gold was in short supply. Stores sold this equipment at a steep markup and made enormous profits. California’s first millionaires were not the prospectors but the equipment suppliers, hence the advice, “During a gold rush, sell shovels.”
The stock market evaluation of the high-tech companies that developed large language models (LLMs) rose 30 percent between November 22, 2022, when ChatGPT went public, and November 22, 2023. The stock of Nvidia, which makes the GPUs used to train LLMs, had increased 400 percent. Its market capitalization increased from $273 billion to over two trillion dollars, today reaching 3.5 trillion dollars. Their high-end H100 GPU is backordered, and their new B200 GPU has 30 times more performance. To update the advice: “During the AI rush, sell GPUs.” Several high-tech companies are even building special-purpose AI chips, such as the Tensor Processing Unit (TPU) designed by Google.
Data Centers are Burning
High-tech companies have many data centers worldwide, large warehouses filled with rack after rack of servers. Most of these are traditional CPUs, but the mix of GPUs and special-purpose AI hardware is fast expanding. New purpose-built AI data centers are beginning to sprout up to meet the demand. CoreWeave has seven large AI data centers online and expects to double that by 2024. A 200,000-square-foot AI data center can cost over $1 billion (Figure 1). Estimates for AI infrastructure, including data centers, networks, and other hardware, “is expected to reach $422.55 billion by 2029, growing at a compound annual rate of 44% over the next six years.” [1] Ten years ago, a data center would draw ten megawatts, but 100 megawatts is the norm today, and the ten largest in North America now average 620 megawatts. Today, AI consumes 2 percent of all the power in global data centers and is expected to reach 10 percent later this year. [2] Microsoft plans to take a nuclear power plant on the three-mile island out of mothballs to power an even larger data center. On January 22, 2025, OpenAI, Oracle, and SoftBank announced an ambitious $500 billion project to build an advanced data center over 10 years.

Figure 1. A large data center can support a million servers in 1 million square feet, requiring 850 MW of power.
High Stakes Games
In the early days of LLMs, academic researchers could build small language models (by today’s standards). LLMs have become so large that only a few major high-tech companies have computing power, enough data, and deep pockets to train them. Researchers at Google introduced transformers, but OpenAI, powered by a billion-dollar investment and cloud support from Microsoft, was the first to go public successfully with ChatGPT. By the time ChatGPT was released to the public, OpenAI had created a for-profit corporation inside their nonprofit and was not releasing technical details, effectively becoming closed AI. [3] Microsoft doubled, redoubled, and re-redoubled down with an additional infusion of $10 billion. It used OpenAI’s GPT-4 to power Bing, its forlorn search engine that suddenly became formidable.
Meta had developed its own LLM called Llama and made it available to a few academic labs, which gave Meta researchers valuable feedback from these beta test sites before rolling out their product. However, Llama’s model and source code was leaked and spread far and wide, making it possible for many groups worldwide to fine-tune the pretrained model and produce inventive new ways to adapt the code for many new uses. OpenAI may have made the genie in the bottle available to the world, but Meta let the genie out of the bottle. Meta eventually made its next-generation Llama 2 open-source, just as Yann LeCun, the Meta AI lab’s chief scientist, told us it would happen. All eight authors of the seminal 2017 paper on transformers have left Google and founded startups, raising billions of dollars in capital. The genie is out of the bottle and is now out of control. [4] Hugging Face is a startup that develops tools for building applications and allows users to share machine learning models and datasets.
The Cost of Chatting
ChatGPT limits the number of requests you can make to GPT-4. This suggests that the data centers’ capacity for processing AI is becoming saturated. More energy is required to run the servers as more users sign up. How much energy does it take to run LLMs? [5] It took months to train GPT-4, running on tens of thousands of GPUs at a cost of $100 million. Estimates for the one-time energy consumption for training GPT-4 are around 5,000 megawatt hours (MWh). To understand what these numbers mean, it takes around 100 megawatts of power to run the New York City subway or around 2,500 MWh daily. The actual cost is not the one-time training cost but the usage cost for processing customer requests, which is 100 MWh daily. Therefore, it takes around $1 million per day for GPT-4 to answer requests. This adds up quickly to 36,500 MWh and $365 million per year and is increasing rapidly.
The cost of computing has halved every two years since the dawn of digital computing in the 1950s and is a billion times cheaper today. This empirical observation, called Moore’s law, ended a few years ago as the sizes of transistors and wires reached the smallest physical limits. However, because chips are getting larger, each chip can do more computing. The latest computer chips have 100 billion transistors on a single chip. With this many transistors, it has become possible to put many cores—complete CPUs—on a single chip. Laptop computers typically have four to eight cores, and GPUs have thousands of cores. The CPU chips in your laptop are about the size of a postage stamp. Cerebras, a company that designs special-purpose computers for AI, has built a chip with 2.6 trillion transistors that is the size of a dinner plate (Figure 2). [6] Their CS-2 wafer-scale chip packs 850,000 cores with superfast on-board memory. The chip is 1,000 times more powerful than a GPU and consumes 15 kilowatts. This super chip can handle a neural network model with 120 trillion weights. On July 2023, G42, an AI company based in Abu Dhabi, purchased a $100 million Condor Galaxy 1 AI supercomputer with 64 Cerebras CS-2 systems containing 54 million cores and 82 terabytes of memory that runs at 4,000 petaflops (10^15 floating point operations per second). The top supercomputer in the world as of this date is Frontier at the Oak Ridge National Laboratory, rated at 1,200 petaflops.
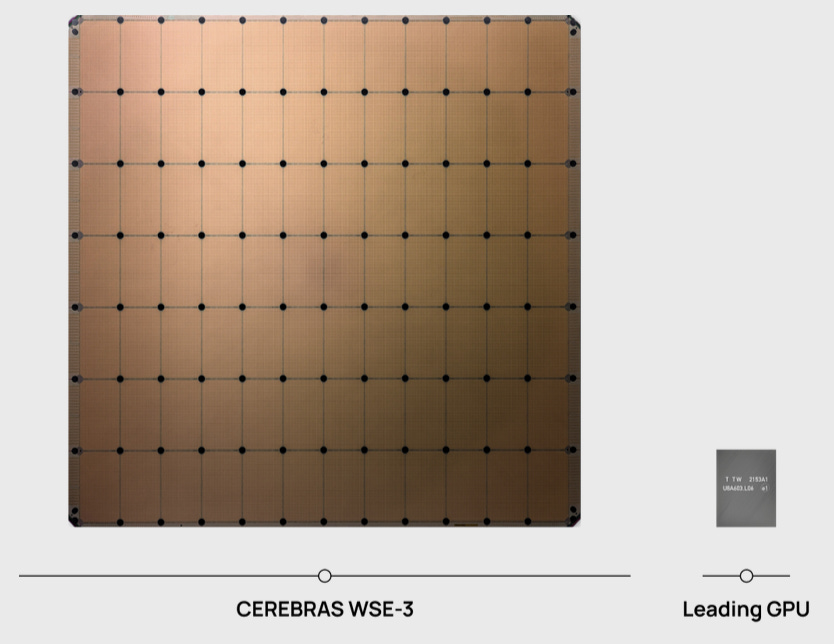

Figure 2. Cerebrus supercomputer on a chip. (Top) A single super chip custom-designed for AI compared with the largest GPU chip. (Bottom) A single wafer-scale chip consumes 15 kilowatts of power and must be water-cooled, which takes up most of the enclosure.
Cerebras has claimed top speeds for AI applications, but over thirty-five hardware companies building AI chips are catching up. Multicore chips can efficiently implement the massively parallel architectures of deep learning networks. With enough cores, the time it takes to process input is independent of the network size. AI can take full advantage of parallel hardware, which is a win-win situation. As models get larger, the hardware gets cheaper, and performance improves. However, the show-stopper is not the computing speed but the required energy.
A Lesson from the Dot-com Bubble
This is not the first time that investments in technology have overreached demand. In the early days of the internet, the rate-limiting bottleneck was the bandwidth of communication to support the increasing demand. The data rate for transmitting video is orders of magnitude greater than text. Fueled by investor enthusiasm, companies laid vast networks of optical fibers, often based on overly optimistic forecasts of bandwidth demand. There was a belief that if the infrastructure were in place, demand would inevitably follow. However, the demand didn’t grow as rapidly as projected, leading to overcapacity.
When the bubble burst in the early 2000s, many telecommunications companies wrote down the value of their fiber optic assets. These write-downs amounted to billions of dollars. Many telecom companies, particularly those that had aggressively expanded their networks during the boom, went bankrupt. These bankruptcies wiped out a significant portion of investor equity. Many fiber optic networks were left unused or underutilized, becoming “stranded assets.”
The telecom industry underwent a period of substantial consolidation as stronger companies acquired the assets of bankrupt or struggling ones, often at drastically reduced prices. This shifted the loss from one company to another but still represented an overall loss of value in the network. Overall, trillions of dollars of market value evaporated when the dot-com bubble burst. Much of this was tied to telecommunication companies that had invested heavily in fiber.
Many of the fiber optic networks deployed during the boom went “silent” and remained underutilized for years. There was just no demand for all of the capacity. However, the fiber cables were not physically removed or destroyed. They remained in the ground, on poles or underwater. What became “silent” or drastically devalued was the monetary value of these assets. The expectations for the revenue the networks would generate were never met. The dot-com bubble burst significantly reduced investor confidence in the telecommunications sector for years.
But all was not lost. The rapid growth of the internet eventually caught up and lit up the fiber optic networks. The winners weren’t the ones who paid for the fiber optic networks but the ones who later used it for streaming audio and video into everyone’s homes. A similar story can be told about the expansion of railroads in the 19th century.
Small Language Models
Microsoft recently released Phi, a family of powerful, small language models with groundbreaking performance at low cost and low latency. [7] LLMs typically hoover data from the internet, a massive amount of words that include contradictory information. Phi was trained on higher-quality data using only 3.8 billion total parameters, matching the performance of highly capable models with hundreds of billions of parameters. Phase 1 training was comprised mainly of web sources and aimed to teach the model general knowledge and language understanding. Phase 2 included synthetic data to teach the model logical reasoning. Phi is more efficient, and a version of it fits on a cell phone. As LLMs migrate to edge devices, you may one day be able to talk to your teapot.

Figure 3. Ranking of Large Language Models by Competition. [8] Pairs of LLMs were compared on different problems to determine the Elo ranking, similar to how chess players are ranked based on their games.
Chatbot Arena is an open platform for crowdsourced AI benchmarking developed by researchers at UC Berkeley SkyLab and LMArena. [9] With over 1,000,000 user votes, the platform ranks the best LLM and AI chatbots. The ranking as of January 26, 2025, has a few surprises (Figure 3). Of the top ten LLMs, four are from Google, including the top two. OpenAI, the previous leader, has three LLMs in the top ten.
The big surprise is DeepSeek, a Chinese company with two LLMS in the top ten, one of which is in fourth place. The US is several years ahead of the world in developing LLMs, which typically cost $100s of millions to train to the highest level of performance. DeepSeek reached this level for only $5.6 million despite the export curbs that have reduced the availability of the latest GPUs to train LLMs. Moreover, it is open source, including code. Not too surprisingly, guardrails prevent comments on the People’s Republic of China. Most LLMs are extensively fine-tuned with expert knowledge, which was not used for DeepSeekR1 but was instead fine-tuned with reinforcement learning, the same way we teach students in schools.
Experts in Silicon Valley are dumbfounded. This illustrates that innovation often arises not at the top of the corporate ladder but with startups that devise new, more efficient algorithms rather than use brute force to solve complex problems. The US also has feisty startups, and Anthropic’s Claude 3.5 Sonnet, in 13th place, is strong on sensitivity to nuance and emotional intelligence. [10] Claude has achieved popularity in Silicon Valley for its superior performance in giving dating advice.
ChatGPT is not the only game in town.
[1] A. Loten, “AI-Ready Data Centers Are Poised for Fast Growth,” Wall Street Journal, August 4, 2023.
[2] P. Sisson, A.I. Frenzy Complicates Efforts to Keep Power-Hungry Data Sites Green, New Yori Times, March 11, 2024.
[3] For some technical details leaked from OpenAI, see Dylan Patel and Gerald Wong, “GPT-4 Architecture, Infrastructure, Training Dataset, Costs, Visions, MoE,” Semianalysis, July 10, 2023, https://www.semianalysis.com/p/gpt-4-architecture-infrastructure.
[4] David Donoho at Stanford has attributed the rapid pace of AI to “frictionless reproducibility” from open source tools and benchmark competitions. (Donoho, D., 2024. Data science at the singularity. Harvard Data Science Review, 6(1)).
[5] Zodhya, “How Much Energy Does ChatGPT Consume?,” Medium, May 20, 2023, https://medium.com/@zodhyatech/how-much-energy-does-chatgpt-consume-4cba1a7aef85.
[6] https://www.cerebras.net/product-chip/.
[7] https://arxiv.org/abs/2404.14219v1
[8] https://openlm.ai/chatbot-arena/
[9] https://lmarena.ai/
[10] https://medium.com/@arijitghosh646/claude-3-5-sonnet-why-its-superior-to-chatgpt-03ae3a5ae00e
Is all of this related to the current interest of the new administration in more energy and new alliances with the tech giants?
As always, an excellent piece of work. Makes you wonder what will appear next. It provokes the following question: Where will these AI's get their electricity to be run, now that it is becoming a scarcity?